

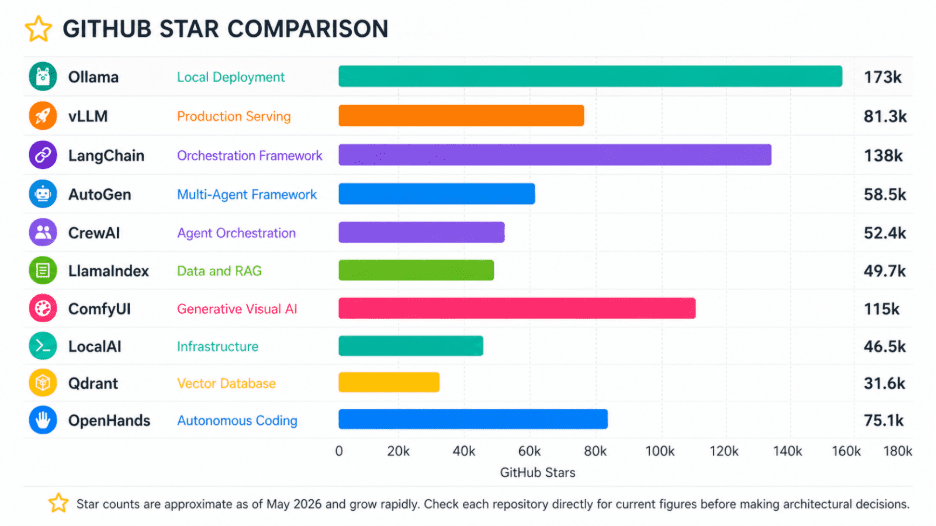
From privacy-first local deployment to autonomous multi-agent orchestration, these open-source repositories are reshaping how production AI gets built and shipped.
The traditional software development lifecycle is undergoing a radical transformation. Codebases are no longer static repositories of logic; they have become living ecosystems driven by artificial intelligence, and the tools powering them are almost entirely open source.
GitHub’s Octoverse report confirmed what developers already sensed: more than 4.3 million AI-related repositories now exist on the platform, representing a 178% year-over-year surge in LLM-focused projects alone. This obsession is not driven by novelty and mere demand. Engineering teams are turning to open-source AI to solve concrete problems such as reducing API latency, breaking free from vendor lock-in, and establishing robust data privacy boundaries while keeping infrastructure costs from spiraling out of control and sustaining competitiveness.
The repositories dominating developer consciousness right now are toward production-ready AI tooling. These are the ten projects that engineering teams are starring, forking, and shipping real products with today.
Holistic AI Engineering Stacks

1. Ollama
Ollama did for local large language models what Docker did for containers: it made them trivially easy to pull and run. Written in Go, it handles model management and serves through a clean API layer, letting developers spin up Llama 3, Mistral, Gemma, or DeepSeek with a single terminal command. Its desktop apps for macOS and Windows lower the barrier enough that even non-developers can run a fully private AI assistant on their own hardware without touching a configuration file.
Salient Traits:
-
Abstracts model quantization and memory management so developers can focus on application logic rather than infrastructure plumbing.
-
Provides a local HTTP API that mirrors standard API structures, making cloud-to-local endpoint swaps completely seamless in existing codebases.
-
Privacy-first by design; no data is transmitted to external services, making it the default choice for sensitive enterprise workloads.
-
Pairs well with Open WebUI for a full self-hosted chat interface, and LangChain for an orchestration framework with distinct models directly into functional pipelines.
2. vLLM

When transitioning AI applications from prototype to production, serving efficiency becomes the critical bottleneck. vLLM solves this through its PagedAttention breakthrough, which manages Key-Value cache memory the way virtual memory operates in traditional operating systems. Traditional LLM serving systems suffer from massive memory fragmentation that severely limits the number of concurrent requests a server can handle before performance degrades.
Salient Traits:
-
Achieves up to 20 times the throughput of standard serving frameworks without sacrificing a single point of output accuracy.
-
Dynamic block allocation eliminates KV cache fragmentation, enabling far more concurrent users per GPU at the same hardware cost.
-
Radically reduces cloud infrastructure spend for businesses scaling AI features for thousands of simultaneous users.
-
Pairs well with LangChain for orchestration, Qdrant for retrieval pipelines, and any OpenAI-compatible client for drop-in integration
3. LangChain
Building a genuinely useful AI application for customers involves sending a single prompt and returning an accurate response. The backend reality of systems requires chaining complex sequences of prompts, querying external databases, and integrating third-party APIs across multiple steps. LangChain remains the standard framework for managing this complexity, with its LangGraph extension reaching v1.0 in late 2025 and becoming the default runtime for production-grade stateful agent workflows.
Salient Traits:
-
The extensive ecosystem of pre-built connectors for tools, memory systems, and data sources dramatically reduces boilerplate across projects.
-
LangGraph brings graph-based agent orchestration with stateful checkpoints, human-in-the-loop support, and time-travel debugging for production systems.
-
LangSmith observability platform provides monitoring, tracing, and debugging for live agent deployments, making AI systems auditable like microservices.
-
Pairs well with LlamaIndex for retrieval, vLLM or Ollama for model serving, and Qdrant as the vector store backend.
4. AutoGen
Microsoft’s AutoGen released 1.0 GA in 2026 with major architectural improvements, and its conversational GroupChat model has carved out a distinct niche in workflows where thoroughness matters more than speed. AutoGen structures agent interaction as multi-turn conversations between a specialized multi-agent stack; one agent writes the code, a second reviews it for security vulnerabilities, and a third executes tests autonomously within a sandboxed environment, all without human coordination.
Salient Traits:
-
Human-in-the-loop oversight mechanisms make it particularly well-suited for sensitive, high-stakes enterprise workflows requiring expert review.
-
AutoGen Studio UI simplifies multi-agent workflow creation for product teams, business analysts, and other professionals with no deep machine learning engineering expertise.
-
It excels in offline, quality-sensitive tasks, including document analysis, legal review, financial modeling, and multi-perspective research synthesis.
-
Pairs well with GPT-4o for primary reasoning, combined with a smaller fine-tuned validation model to reduce total token spend significantly.
5. CrewAI
While multi-agent systems are compelling in theory, running them reliably in corporate production environments requires proper governance and structure. CrewAI addresses this by treating agents as members of a cohesive crew, each with defined roles, explicit goals, and operational protocols governing how they collaborate. Its API stabilized in late 2025, and enterprise-grade observability and scheduling features have made it production-ready for repeatable workloads.
Salient Traits:
-
Role-based agent syntax reads closer to a project brief than a programming spec, dramatically lowering the barrier for product teams to build effective agents.
-
Fully model-agnostic, which supports GPT, Claude, Gemini, and locally hosted Llama models via Ollama within the same crew configuration.
-
Ideal for content creation pipelines, market research automation, competitive analysis, and multi-step devOps monitoring workflows.
-
Pairs well with Claude’s latest models for nuanced role-based reasoning. Use Ollama-hosted Mistral for cost-efficient, lower-stakes crew tasks to cut token spend by 30–50%.
6. LlamaIndex
A persistent obstacle when deploying LLMs in enterprise environments is that models have no knowledge of a company’s private, internal data. LlamaIndex functions as the essential data framework connecting isolated internal data sources with powerful language models. It provides connectors capable of ingesting PDFs, Slack channels, Notion workspaces, and SQL databases, then structures that data into optimized indices for contextually accurate, lightning-fast retrieval during user queries. Its new feature enables the activation of auto-correction loops and power LLMs with agentic AI.
Salient Traits:
-
Handles complex data chunking, vector embedding creation, and hierarchical indexing automatically, saving teams weeks of custom data pipeline engineering.
-
Purpose-built for enterprise knowledge bases, transforming static documentation into queryable, always-current intelligence that answers using real data.
-
Integrates directly with every major vector database and LLM provider, enabling flexible, modular deployment architectures that adapt as the stack evolves.
-
Pairs well with Qdrant as the vectorDB backend, vLLM for serving retrieved context, and LangChain or CrewAI for downstream agent orchestration.
7. ComfyUI
The generative AI explosion extends far beyond natural language processing into computer vision and synthetic media. While web-based interfaces for Stable Diffusion exist, serious developers and creative engineers have largely migrated to ComfyUI for its precision and reproducibility. Its node-based graphical interface lets developers construct exact image generation pipelines by connecting modular functional blocks, retaining full control over noise schedules, latent space manipulations, and advanced conditioning steps.
Salient Traits:
-
Saves the complete node configuration directly into generated image metadata, making complex visual workflows instantly reproducible across distributed teams.
-
Modular architecture allows swapping individual pipeline components — models, samplers, upscalers — without rebuilding the entire generation workflow from scratch.
-
Enables creative and marketing teams to automate visual content generation pipelines at scale with consistent, auditable quality controls baked in.
-
Pairs well with LocalAI for a self-hosted model backend, and LangChain or n8n for embedding image generation into broader automated content workflows.
8. LocalAI
Many production platforms were built with hardcoded integrations pointing to proprietary cloud APIs, and migrating them to self-hosted infrastructure typically means a costly, top-to-bottom codebase to rewrite. LocalAI eliminates this problem by serving as a free, self-hosted, drop-in replacement REST API that matches the OpenAI specification exactly. Developers can repurpose their existing application code, update a single environment variable, and instantly run their software using open-source models on their own hardware.
Salient Traits:
-
Supports audio transcription, image generation, and text embeddings on standard consumer hardware without requiring specialized cloud GPU infrastructure.
-
Zero application code changes required — every existing OpenAI-compatible client library and SDK works without modification against the local endpoint.
-
Delivers immediate improvements to corporate data privacy posture and cost reduction initiatives without introducing architectural debt or migration risk.
-
Pairs well with Ollama for model management and ComfyUI for multimodal generation, forming a coherent, fully self-hosted AI infrastructure stack.
9. Qdrant
As AI applications integrate semantic search, recommendation algorithms, and persistent memory retention, the underlying database infrastructure must evolve to handle vector embeddings at scale. Qdrant is a high-performance vector similarity search engine written in Rust, designed specifically to handle massive multi-dimensional vector datasets under intense, low-latency production workloads. Its Rust foundation provides extreme hardware efficiency that Python-based alternatives simply cannot match under production-level concurrent load.
Salient Traits:
-
Advanced payload filtering enables precise, context-aware retrieval that goes far beyond what standard keyword search or full-text indexing can deliver.
-
Horizontal scaling and cloud-native architecture make it viable for semantic search across datasets spanning billions of unique vectors without performance degradation.
-
Consistently returns results within milliseconds at enterprise scale, making it the preferred vector backend for teams building customer-facing, latency-sensitive applications.
-
Pairs well with LlamaIndex for data ingestion, vLLM for serving retrieved context, and LangChain or CrewAI for downstream agent orchestration.
10. OpenHands
The open-source push toward fully autonomous software agents has reached a meaningful milestone with OpenHands (formerly OpenDevin). This repository has transcended simple scripting to establish a rigorous, Docker-sandboxed execution framework capable of running complex, multi-file software engineering tasks entirely from natural language instructions. Operating natively within secure virtual containers, OpenHands safely handles real-world workflows like refactoring legacy modules and upgrading sprawling dependency trees without human monitoring.
Salient Traits:
-
Docker sandbox isolation ensures that autonomous code execution cannot affect host systems or touch production environments under any conditions.
-
Deep integration with agentic IDEs like Windsurf enables a powerful local-to-cloud split workflow: fast in-editor iteration, then seamless delegation to cloud execution.
-
Frees developers from monitoring long-running compilation and QA processes, merging local development speed with cloud-scale autonomy in one unified experience.
-
Pairs well with LangChain for orchestration, vLLM for model serving, and AutoGen for adding multi-agent code review and validation on top of generated output.


