

Introduction
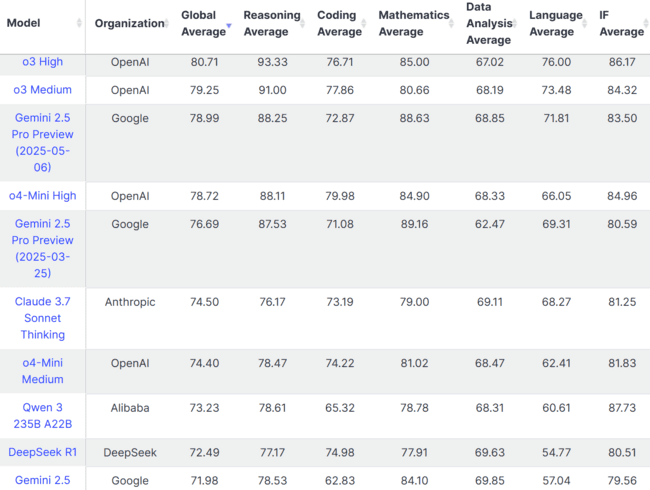
The race for artificial intelligence supremacy has reached a new milestone as OpenAI’s latest creation, o3 High, emerges as the undisputed champion in comprehensive language model benchmarking. With an impressive global average score of 80.71, this groundbreaking model has redefined what’s possible in machine intelligence, demonstrating exceptional capabilities across every major domain of cognitive tasks.
The Champion’s Performance
What sets o3 High apart isn’t just its top ranking—it’s the remarkable consistency across diverse intellectual challenges. The model achieved a staggering 93.33 in reasoning tasks, showcasing an almost human-like ability to process complex logical problems. In coding environments, it maintained a solid 76.71 average, while mathematical problem-solving yielded an impressive 85.00 score. Even in nuanced areas like data analysis (67.02) and language understanding (76.00), o3 High demonstrated robust performance that outpaces its nearest competitors.
Perhaps most remarkably, o3 High excelled in instruction-following tasks with an 86.17 average, indicating superior comprehension of user intent and context. This combination of raw intelligence and practical usability represents a significant leap forward in model development.
So What Does This Mean?
If you’re choosing a model to power your business, research, creative work, or day-to-day tools, you want one that gets it right the first time. o3 High offers that rare combination of breadth and depth—high-level thinking with practical output. It’s not just “smart”; it’s genuinely helpful, reliable, and consistent across tasks.
In a year where many are still figuring things out, OpenAI has built something that just works—and works better than anything else.
The Anatomy of a Leader
o3 High’s superiority isn’t built on one or two standout skills. It’s built on consistency, precision, and balance—a rare combination in a landscape full of trade-offs.
| Skill Area | o3 High Score |
| Reasoning | 93.33 |
| Math | 85.00 |
| Coding | 76.71 |
| Data Analysis | 67.02 |
| Language | 76.00 |
| Instruction Following (IF) | 86.17 |
The Competitive Landscape
The current leaderboard reveals a fascinating three-way battle at the top. OpenAI maintains its dominance with o3 Medium securing second place at 79.25, while Google’s Gemini 2.5 Pro Preview closely follows at 78.99. This tight competition at the summit demonstrates how rapidly the field is advancing, with multiple organizations pushing the boundaries of what these systems can achieve.
Notably, OpenAI’s newer o4-Mini High model claimed fourth position with 78.72, suggesting that even their smaller, more efficient models are competitive with the flagship offerings from other major players. This trend points toward a future where high-performance intelligence becomes more accessible and cost-effective.
Specialized Strengths Across Providers
While OpenAI dominates the overall rankings, different models show distinct advantages in specific domains. The top performers reveal fascinating patterns of specialization:
| Domain Leaders | Model | Organization | Score | Key Strength |
| Overall Performance | o3 High | OpenAI | 80.71 | Consistent excellence across all domains |
| Reasoning Master | o3 High | OpenAI | 93.33 | Exceptional logical problem-solving |
| Mathematics Expert | Gemini 2.5 Pro Preview | 89.16 | Advanced mathematical computation | |
| Coding Specialist | o4-Mini High | OpenAI | 79.98 | Superior programming capabilities |
| Data Analysis Leader | DeepSeek R1 | DeepSeek | 69.63 | Strong analytical processing |
| Instruction Following | Qwen 3 235B A22B | Alibaba | 87.73 | Excellent command comprehension |
The Reasoning Revolution
The top-performing models consistently excel in logical problem-solving, suggesting that the next generation of language models will be characterized by their ability to think through complex problems systematically rather than simply generating text based on patterns.
This shift toward reasoning-focused development appears to be the key differentiator separating the leaders from the rest of the field. Models that can break down problems, consider multiple approaches, and arrive at well-reasoned conclusions are emerging as the clear winners in comprehensive evaluations.
What This Means for You
Think of this leaderboard as a preview of the future sitting right in front of us. OpenAI’s o3 High isn’t just another incremental improvement—it’s setting the bar so high that it’s fundamentally changing what we can expect from these systems. Here’s what’s really happening: the best models are getting dramatically better while the gap between leaders and followers keeps growing. If you’re running a business or working on projects that could benefit from AI assistance, this matters more than you might think.
Why should you care?
The technology landscape is shifting beneath our feet faster than most people realize. Companies that figure out how to work with these advanced models now will have a massive head start over those who wait. It’s like having access to a brilliant research assistant, coding partner, and analytical expert all rolled into one.
The bottom line: We’re not just seeing better chatbots—we’re watching the birth of thinking machines that can actually reason through problems the way humans do, but with access to vastly more information and processing power.
The question isn’t whether this technology will change how we work and solve problems. The question is whether you’ll be ready to use it when it matters most for your goals.




