DeepSeek-OCR: Advanced Multimodal Optical Character Recognition Model
DeepSeek-OCR is an advanced optical character recognition (OCR) model developed by DeepSeek AI, specializing in effective visual-text compression for extracting textual information from complex images. It is engineered as an image-text-to-text multimodal model capable of processing intricate visual inputs containing text and converting them into machine-readable output with high precision. By leveraging transformer-based vision-language modeling, DeepSeek-OCR integrates deep visual perception with contextual language understanding to boost recognition performance. The model uses innovative context-aware optical compression techniques, enabling robust text extraction even in challenging visual conditions such as handwritten documents or natural scene text.
Designed as a large-scale model with approximately 6.67GB in weights optimized via safetensors, DeepSeek-OCR balances high-accuracy OCR and resource-efficient inference. Its training involved extensive multimodal datasets tailored specifically for OCR and visual-text alignment, employing a cutting-edge blend of machine learning optimization strategies and optical compression algorithms. This comprehensive approach allows DeepSeek-OCR to outperform traditional OCR systems, particularly in tasks demanding fine-grained text extraction from diverse image contexts like document analysis, multilingual handwriting recognition, and natural scene reading.
For practical applications, DeepSeek-OCR excels in digitizing scanned documents, enhancing content accessibility, and powering downstream use cases such as document indexing and automated language translation. The model is open-source with a permissive license and hosted openly on Hugging Face and GitHub, encouraging community collaboration and transparency. It is compatible with popular machine learning frameworks including PyTorch and supports integration with the vLLM inference acceleration framework, facilitating large batch processing and efficient PDF content extraction workflows. Optimal deployment requires GPUs with ample memory due to the model size and input complexity.
Link: https://huggingface.co/deepseek-ai/DeepSeek-OCR
PaddleOCR-VL: Ultra-Compact Multilingual Document Parsing Model
PaddleOCR-VL, developed by Baidu’s PaddlePaddle team, is an ultra-compact state-of-the-art vision-language model optimized for multilingual document parsing. With only 0.9 billion parameters, it achieves remarkable precision in recognizing complex document elements including text, tables, formulas, and graphics across diverse languages. Featuring a NaViT-style dynamic resolution visual encoder combined with the ERNIE-4.5-0.3B language model, PaddleOCR-VL captures intricate visual layouts and semantic relationships efficiently.
Trained on extensive datasets representing varied document types such as academic papers and invoices, PaddleOCR-VL excels at element-level recognition and page layout parsing. It outperforms larger models on benchmark datasets like OmniDocBench v1.5 due to its optimized design. Its lightweight nature makes it ideal for on-device OCR processing and deployment in resource-constrained environments. PaddleOCR-VL integrates seamlessly with the PaddlePaddle framework, supporting rapid deployment for industrial-grade automated document analysis, invoice processing, and multilingual OCR scenarios.
Link: https://huggingface.co/PaddlePaddle/PaddleOCR-VL
HunyuanWorld-Mirror: Large-Scale General-Purpose Language Models
HunyuanWorld-Mirror is a repository representing the Tencent Hunyuan family of large-scale AI models focusing on general-purpose large language understanding. These models leverage advanced transformer and mixture-of-experts (MoE) architectures with parameter counts scaling into tens of billions. For instance, Hunyuan-MoE-A52B, with 52 billion parameters, represents one of the industry’s largest open-source MoE models.
Training encompasses massive web-scale and multi-domain datasets emphasizing multi-task learning, multi-lingual comprehension, and advanced reasoning capabilities. These models support a variety of natural language processing tasks including text generation, summarization, and translation, delivering state-of-the-art performance benchmarks. Primarily targeting research and enterprise environments requiring scalable inference infrastructure, HunyuanWorld-Mirror integrates robust engineering aligned with Tencent’s AI leadership.
Link: https://huggingface.co/tencent/HunyuanWorld-Mirror
Qwen3-VL-8B-Instruct: Advanced Multimodal Vision-Language Model
Qwen3-VL-8B-Instruct is an 8-billion-parameter multimodal vision-language transformer model from the Qwen series, designed for sophisticated visual-text reasoning and understanding. Architected with innovations such as Interleaved-MRoPE for temporal reasoning and DeepStack for refined visual-text alignment, it supports massive context windows up to 256K tokens natively (extendable to 1 million tokens). This enables processing long documents, complex scenes, and videos cohesively.
Trained on multifaceted datasets including language, coding, reasoning, image-text, and video corpora, it excels in applications such as document parsing, visual question answering, and 3D spatial reasoning. The model boasts robust OCR capabilities across 32 languages and supports instruction tuning for interactive tasks. Released under permissive licenses and integrated with transformers, Qwen3-VL-8B-Instruct is suitable for AI assistant developments, multimedia analytics, and advanced human-computer interaction systems.
Link: https://huggingface.co/Qwen/Qwen3-VL-8B-Instruct
Krea Realtime 14B: Real-Time Autoregressive Video Generation Model
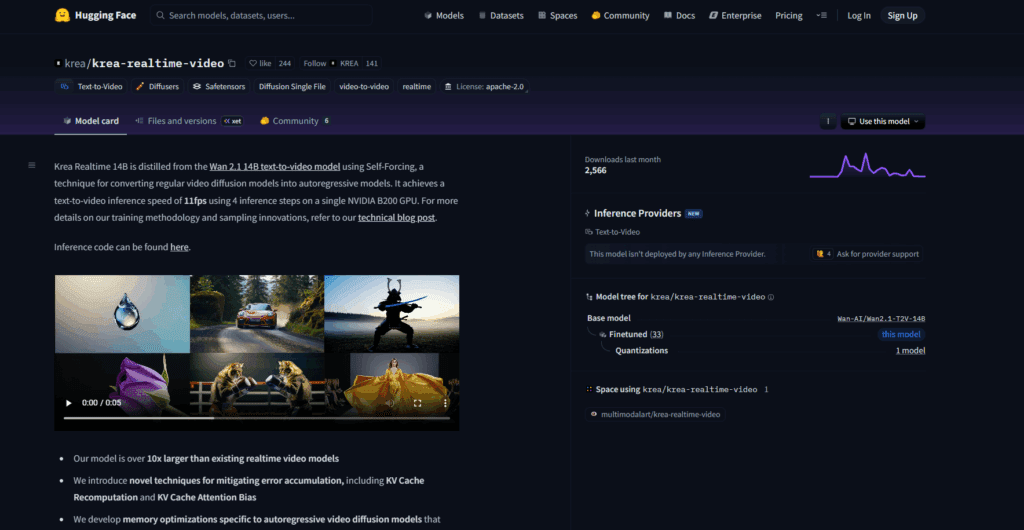
Krea Realtime 14B is a 14-billion-parameter autoregressive video generation model optimized for real-time interactive long-form video synthesis. Produced via novel Self-Forcing distillation techniques, it transforms diffusion video generation into autoregressive frame synthesis, significantly reducing inference steps from about 30 to just 4. This enables ultra-fast generation workflows delivering first-frame results within one second.
Supporting inputs such as streaming webcams, canvas drawings, and video streams, Krea Realtime is ideal for interactive AI-driven video editing, creative content creation, and media manipulation in dynamic environments. Accessible through the Hugging Face Diffusers library, it addresses a major challenge in AI video synthesis: delivering low-latency, controllable video generation. Krea AI focuses on developing accessible, real-time AI tools for content creators.
Link: https://huggingface.co/krea/krea-realtime-video
Nanonets-OCR2-3B: Transformer-Based Intelligent Document Parsing Model
Nanonets-OCR2-3B is a powerful 3-billion-parameter OCR model designed for transforming documents into structured markdown text with intelligent semantic content tagging. Supporting multi-modal inputs, it excels in recognizing complex document layouts including tables, formulas, and unstructured text. The model utilizes optimized transformer architectures tailored for OCR and advanced layout analysis across languages.
With training on diverse intelligent document processing benchmarks, Nanonets-OCR2-3B achieves high accuracy in automated document digitization and content indexing workflows. Offered under a specialized research license and suitable for local GPU environments, it targets enterprise applications demanding reliable structured data extraction and efficient document AI pipelines.
Link: https://huggingface.co/nanonets/Nanonets-OCR2-3B
Qwen-Image-Edit-Rapid-AIO: Accelerated AI Image Editing Model
Qwen-Image-Edit-Rapid-AIO is an accelerated all-in-one model engineered for fast and versatile AI-based image editing and text-to-image generation. Combining various accelerator modules, VAE, and CLIP encoders, it streamlines efficient visual editing workflows supporting both NSFW and SFW content variants. Progressive versions introduce specialized Lightning LoRAs and mixed-step approaches enhancing fidelity and generation quality.
Architecturally based on Qwen image editing models with diffusion techniques, it is optimized for rapid loading and inference, enabling integration in interactive and ComfyUI pipelines. It suits use cases like creative image transformations, rapid visual prototyping, and text-guided image manipulation in real-time. Open sourced under Apache-2.0 license, it supports advanced AI-driven content creation tools.
Link: https://huggingface.co/Phr00t/Qwen-Image-Edit-Rapid-AIO
next-scene-qwen-image-lora-2509: Cinematic Image Sequence Generation Adapter
next-scene-qwen-image-lora-2509 is a Low-Rank Adaptation (LoRA) adapter fine-tuned on the Qwen-Image-Edit 2509 base for generating cinematic image sequences with coherent visual flow. It enriches the base model with enhanced camera dynamics and narrative flow understanding, facilitating smooth next-scene transitions akin to a film director’s storytelling.
The lightweight (~295MB) adapter is designed for efficient cinematographic AI-generated content, storyboarding, and pipeline use cases requiring sequential visual coherence. Distributed under an open license, it is popular for users employing ComfyUI and similar frameworks to create frame-by-frame video or storyboard AI content.
Link: https://huggingface.co/lovis93/next-scene-qwen-image-lora-2509
MobileLLM-Pro: Compact On-Device Language Models Optimized for Efficiency
MobileLLM-Pro is a family of optimized sub-billion parameter language models developed by Meta to enable on-device natural language understanding with high efficiency. These models incorporate 4-bit Quantization-Aware Training (QAT) for reduced size while maintaining task performance. They compete effectively in question answering, tool invocation, rewriting, and summarization tasks.
The training pipeline encompasses base pre-training, instruction tuning, and quantization readiness stages. MobileLLM-Pro democratizes access to powerful language models in resource-constrained environments such as mobile and edge devices, minimizing cloud dependence. Released under research-focused licenses, the models support PyTorch and CPU/accelerator inference, with standout features in compact footprint and robust on-device AI processing.
Link: https://huggingface.co/facebook/MobileLLM-Pro
Qwen3-VL-32B-Instruct: Large-Scale Vision-Language Model with Extensive Context
Qwen3-VL-32B-Instruct is the flagship 32-billion-parameter vision-language model in the Qwen series, delivering leading-edge performance in text understanding, visual perception, video dynamics, and spatial reasoning. Incorporating advanced techniques like Interleaved-MRoPE for long-context temporal reasoning and DeepStack for precise visual-text alignment, it supports extensive multi-modal inputs and context lengths suitable for complex document parsing and agent control tasks.
Instruction-tuned for interactive applications, this model excels in visual question answering, document analysis, and multi-modal reasoning. Trained on diverse web-scale and synthetic datasets with reinforcement learning enhancements, it ranks among the top-tier open-source VL models with broad OCR language coverage and robust real-world applicability. Permissively licensed for research and commercial adaptation.
Link: https://huggingface.co/Qwen/Qwen3-VL-32B-Instruct
Arch-Router-1.5B: AI Query Routing for Multi-LLM System Optimization
Arch-Router-1.5B is a compact 1.5-billion-parameter AI model from Katanemo Labs devised to optimize large language model (LLM) system architectures via intelligent query-to-domain routing. It maps incoming queries to contextually appropriate sub-models or actions based on domain specificity (e.g., finance, travel) or task type (e.g., summarization, Q&A), enhancing resource efficiency and user experience.
Trained using multi-domain datasets and reinforcement learning to align with user preferences, Arch-Router-1.5B supports modular, scalable deployment in multi-LLM platforms. Released under research-focused licenses, it integrates easily with LLM orchestration systems to improve computation usage and enable preference-aligned AI workflows.